
I was curious how machines would interpret a cringe comedy sketch show, so I re-watched all 86 sketches in I Think You Should Leave by Tim Robinson. I used machine learning methods to decode the sentiment of every phrase uttered and the emotion of every face detected.
Methodology
- Scrape metadata (sketch-level data, including time stamps)
- Prepare data (transcripts and videos)
- Text classification for sentiments
- Face detection
- Emotion classification
Scraping the metadata
I found a Netflix blog post with all the timestamps and names of each sketch. I used this to create a metadata file that would be used to process the video data.
While re-watching the show, I assigned my own category to each of the sketches and added it to the metadata file. The top three are office scenarios, parties, and TV commercials.
Preparing the Transcripts
For the transcripts I wasn't able to scrape the site, but it was easy enough to copy and paste from the I Think You Should Leave database. I cleaned up the transcripts using the NLP library spaCy to identify and extract full sentences.
Text Sentiments
I tried a few models for sentiment/emotion classification. The first one was DistilBERT which only provided positive/negative results. I ended up choosing GoEmotions ("SamLowe/roberta-base-go_emotions") which includes 28 emotions. The model found 25 emotions in the transcripts overall. Interestingly, the emotion it detected the most was 'neutral'.
Detecting Faces
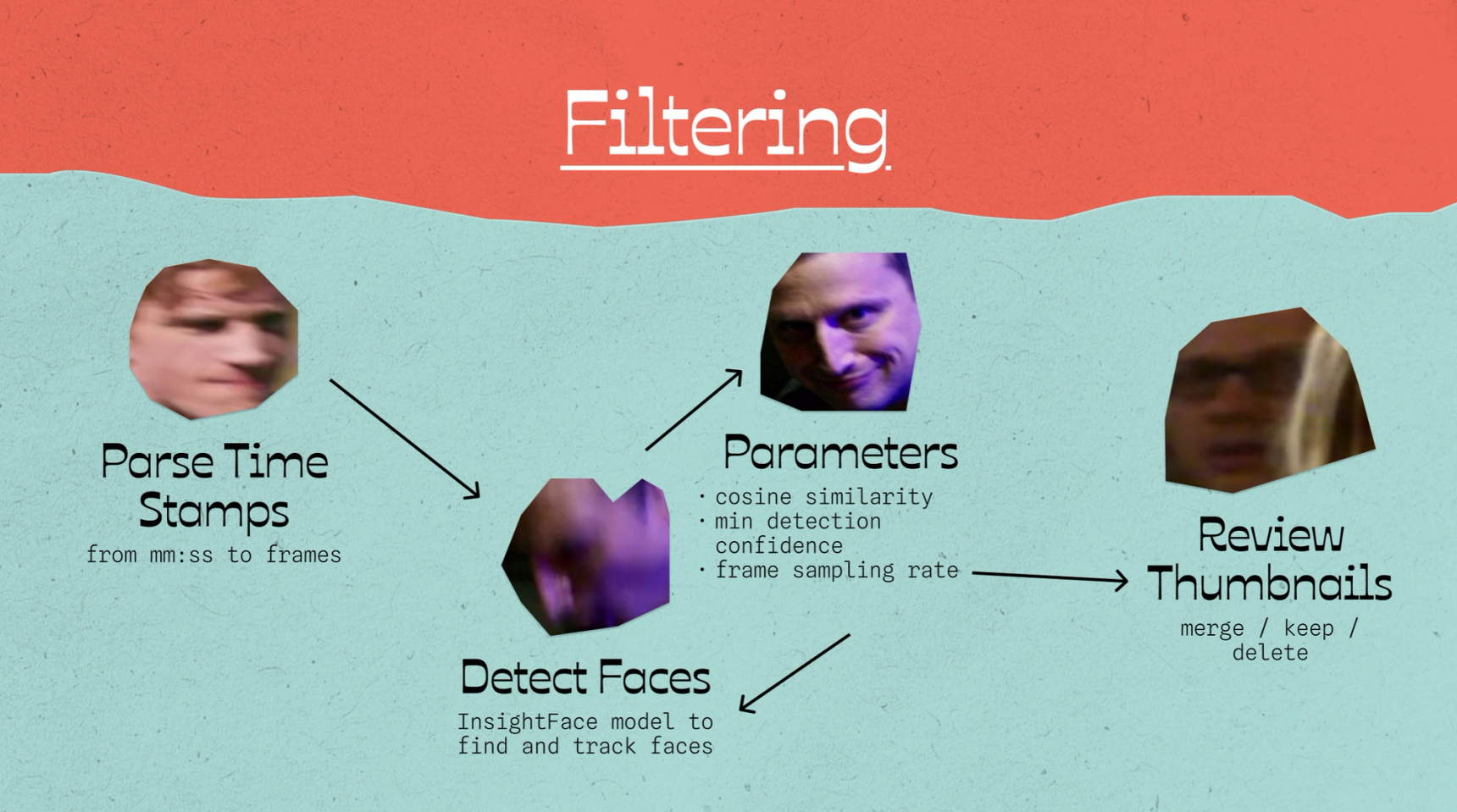
Next, I wanted to compare with video sentiments using a model called InsightFace to detect and track faces. First, I parsed the time stamps from the metadata into seconds and then I ran some tests to determine the frame sampling rate, cosine similarity threshold, and minimum detection confidence. I decided somewhat arbitrarily to capture a face every 18 frames (just under 1 second). Capturing every frame would've taken way too long and I would have burnt through all of my free student credits on Google Colab, and 1 frame per second didn't feel like enough. Some emotional reactions felt faster than that.
Initially, the cosine similarity threshold was set to 0.5 and it was identifying too many characters. For example, 16 characters were identified in a sketch that only had 4 people in it. Decreasing the threshold to 0.3 was perfect for getting the results I wanted. I watched a few sketches to verify that it correctly identified which faces belonged to the same person. I added some logic so I could interrupt the process and restart it if needed. Overall it took hours and lots of experimentation to get this the results I wanted.
Since a lot of the background characters weren't often in clear view and didn't tend to add much to the plot I set the minimum detection confidence to 0.8 which worked well for ignoring low-confidence detections.
There were still more characters captured than I needed, so I manually reviewed the thumbnails to weed out the unimportant ones. Automating this probably would've taken an equally arduous amount of time, so I watched every episode... again. I tracked these in a CSV file and then converted it into a JSON format to make it machine-parsable. I used this JSON to run some merge/keep/delete functions based on my manual review.
Emotion Detection

I searched long and hard for a facial expression model that would match the wide range of sentiments that GoEmotions could do. This one was the closest, I believe it does 27 emotions, but unfortunately I couldn't get it to work for me.
I settled on this vision transformer model that is trained on FER2013, MMI facial expressions, AffectNet datasets. It only classifies 7 facial emotions. Although the results were not as nuanced as the transcript results, the top emotion it classified was still 'neutral'. I went all out with Google Gemini for this one, I asked it so many questions that it eventually told me that it was finished all the tasks instead of offering more help.
Closing Thoughts
Considering the topics that the sketches cover, most of them are a little mundane at face value: office interactions, parties full of middle-aged people, infomercials and traditional tv commercials, dating faux-pas, restaurant etiquette, driving... mostly everyday situations that we find ourselves in, made awkward. It's no wonder that most of the sentiments were 'neutral'. It would take some more advanced implementation to consider the context surrounding each sentence or individual face, and even then, the humour in a show like this can be extremely subjective, probably even more than other comedic genres. Most machine learning methods for identifying humour are based on pattern recognition and some even rely on the presence of a laugh track. The methods I used are nowhere near being able to understand a cringe comedy and what makes it funny. I find relief in that, because I think the writing is brilliant and I'd never want a machine to be able do this, anyway.